Das Z-GPRS3, ausgeliefert von der italienischen Firma Seneca, ist ein technisch aktuelles Anzeige- und Kontrollgerät für Messwerte aller Art. Es besitzt die Möglichkeit, die Werte über ein GPRS Interface zu übertragen und in Reports anzuzeigen. Dieses Reporting basiert auf moderner Technologie und kann daher das Berichtsfenster aktualisieren, ohne dass die gesamte Webseite im Browser neu aufgebaut werden müsste. Die Technologie dahinter wird in einer Bibliothek namens jQuery gekapselt.
Wenn man sich nun die Berichte über das Internet ansieht, sieht man eine sehr lange initiale Ladezeit. Wir reden hier von bis zu drei Minuten. Nach dieser Zeit werden die Berichte ganz normal und ohne weiteres Warten dargestellt.
Aus diesen Beobachtungen heraus haben wir einen Mitschnitt der Browserkommunikation mittels der Entwicklerwerkzeuge durchgeführt. Wie man am Screenshot deutlich sehen kann werden drei große Dateien geladen bevor die einzelnen Messwerte in kleinen Datenpaketen nachgeladen werden. Diese drei Dateien verzögern also die gesamte Antwortzeit des Systems.

Im ersten Versuch einer Optimierung sind wir an der „same origin policy“ gescheitert, welche besagt, dass die Anfragen immer zum gleichen Server zurück gehen müssen, von welchem auch jQuery geladen wurde.
Was sollten wir nun machen? Eine Option wäre, die Verbindung des Seneca Geräts über LTE abzuwickeln. Durch die zusätzlich benötigte Hardware ist dies aber für die aktuelle Installation in einem solarbetriebenen, autonomen Umfeld eher ungeeignet.
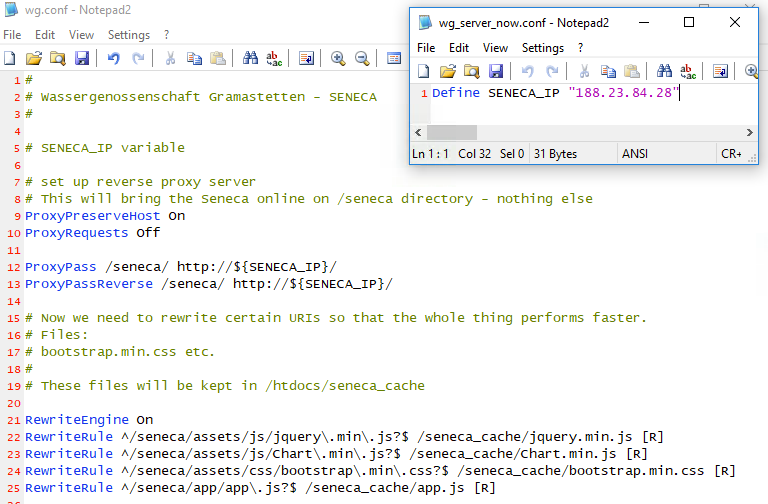
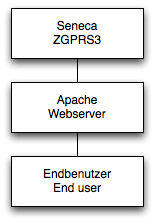
Die andere Art, die Aufgabenstellung zu lösen ist es, das Seneca Gerät über einen Zwischenserver zu verbinden, welcher das Laden von verschiedenen Quellen überwachen kann. Wir haben uns in diesem Zusammenhang für den Apache Webserver entschieden, welchen wir im „reverse proxy“ Modus betreiben. In diesem Modus werden alle Anfragen von den Clients über diesen Webserver an das Seneca Gerät weitergeleitet. Bis zu diesem Teil hat sich die bisherige Funktionsweise und auch die Architektur kaum geändert. Durch den zwischengeschalteten Server wird es aber möglich, für Zugriffe auf spezifische Adressen das Ladeverhalten zu beeinflussen.
Wir haben also die zuvor ermittelten Dateien in ein öffentlich zugreifbares Verzeichnis auf dem gleichen (wichtig!) Server kopiert. Dann haben wir den Apache Webserver so konfiguriert, dass bei Zugriffen auf diese Dateien eine Umleitung auf das Verzeichnis am Webserver (und nicht auf dem Seneca Gerät) erfolgt.
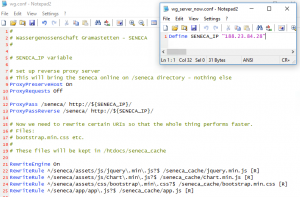
Wenn man das so macht, gehen die Zugriffe auf diese großen Dateien nicht bis auf das Seneca Gerät zurück, aber die Anfragen für die einzelnen Messwerte werden sehr wohl bis auf das GPRS Gerät umgeleitet.
Fröhliches Messen!